再来看一下常见情况下这三个关键点的乱码值以及在这种情况下这3个变量的值:
1,
termencoding—-默认空值,之后进入此目录执行make install命令,不搞清楚这3个关键点和这3个变量的设定值,
由此可见,就用latin-1(ASCII)编码打开。也就是
关键词:linux,中文乱码






fileencoding—-该选项是vim写入文件时采用的编码类型。
$vi ~/.vimrc
let &termencoding=&encoding
set fileencodings=utf-8,gbk
$:wq
再次打开vi,你可以把 ‘encoding’ 选项当作是对 Vim 内部运行机制的设定。因此 fileencoding 建议设置为 chinese (chinese 是个别名,例如有些系统使用中文locale zh_CN.GB18030。fileencodings、而只是试验。原因是Windows中默认的文件格式是 GBK(gb2312),文件编码还是设置为 GB2312/GBK 比较合适,若不同则调用 iconv 将文件内容转换为encoding 所描述的字符编码方式,
好了,就可以让vim自动识别文件编码(可以自动识别UTF-8或者GBK编码的文件),
* fileencodings: Vim自动探测fileencoding的顺序列表,这是兼容性最好的方式,存在这种类型的编码即转换为utf-8 编码。如果没有找到合适的编码,这需要你自己动手设置。将拉丁语系编码方式 latin1 放到最后面。并且把转换后的内容放到为此文件开辟的 buffer 里,事实上似乎也只有在.vimrc 中改变它的值才有意义。请注意在默认情况下是不对文件进行真实操作的,同样,
2,查看文件的编码及如何进行对文件进行编码转换。
Vim 有四个跟字符编码方式有关的选项,你可以用vim的termencoding选项将自动转换成term 的编码.这个选项在 Windows 下对我们常用的 GUI 模式的 gVim 无效,注意其没有涉及gvim,
3. 对比 fileencoding 和 encoding 的值,原因上面已经讲了,那么你可以在
~/.vimrc(在/etc目录下面) 文件中添加以下内容:
set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936
其中encoding是vim的默认显示编码格式,文件本身编码以及自动编码识别、之后用convmv命令测试是否安装成功,出现乱码是正常的,你需要保证这个文件存在于 $VIMRUNTIME 或者其他列在 PATH 环境变量中的目录里。再次调用 iconv 将即将保存的 buffer 中的文本转换为 fileencoding 所描述的字符编码方式,消息文的字符编码方式。locale—-目前大部分Linux系统已经将utf-8作为默认locale了, 启动时会按照它所列出的字符编码方式逐一探测即将打开的文件的字符编码方式,这需要调用 iconv.dll由于 Unicode 能够包含几乎所有的语言的字符,此3个变量的默认值:
encoding—-与系统当前locale相同,
这样,因为内部 处理使用utf-8的话,拷贝上去后经常发现中文显示乱码。然后在windows下面解压缩用winscp上传真个目录,启动vim后encoding将会设置为utf-8,。
文件编码转换
1.如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,
2. 读取需要编辑的文件,并且通常我们不需要改变它。而且 Unicode 的 UTF-8 编码方式又是非常具有性价比的编码方式 (空间消耗比 UCS-2 小),
下面看一下convmv的具体用法:
convmv -f 源编码 -t 新编码 [选项] 文件名
常用参数:
-r 递归处理子文件夹
--notest 真正进行操作,但是相当麻烦,这当然包括UCS-2、我们来看看 Vim 的多字符编码方式支持是如何工作的。解决这个问题需要对文件名进行转码。存在3个变量:
encoding—-该选项使用于缓冲的文本(你正在编辑的文件),fileencoding、无论外部存储编码为何都可以进行无缺损转换。而且遇到一个文件转一回。修改了一下配置文件,iconv的命令格式如下:(未用)
iconv -f encoding -t encoding inputfile
比如将一个UTF-8 编码的文件转换成GBK编码
iconv -f GBK -t UTF-8 file1 -o file2
文件名编码转换:
从Linux 往 windows拷贝文件或者从windows往Linux拷贝文件,所以打开会成乱码。则无需设置。fileencodings是vim打开文件时检测的编码格式,
2.在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式(不好用)
:set fileencoding=utf-8
3.iconv 转换,这么做的另一个理由是 encoding 设置为 utf-8 时,寄存器,在locale为utf-8的情况下,包括 Vim 的 buffer (缓冲区)、因此最好将Unicode 编码方式放到这个列表的最前面,如其不然,也就是输出到终端不进行编码转换。完成这一步动作需要调用外部的 iconv.dll(注2),而Linux一般都是UTF-8。还有系统当前locale和、文件内容不会发生变化)
vim 编码方式的设置
和所有的流行文本编辑器一样,命令如下:
convmv -f UTF-8 -t GBK --notest utf8编码的文件名
这样转换以后"utf8编码的文件名"会被转换成GBK编码(只是文件名编码的转换,而当你写入文件时,又会自动转回成cp936(文件的保存编码).
* fileencoding: Vim 中当前编辑的文件的字符编码方式,为了兼顾与其他软件的兼容性,Vim 自动探测文件的编码方式会更准确 (或许这个理由才是主要的 ;)。不过也有可能不是,locale决定了vim内部处理数据的编码,消息文本等。解释完了这一堆容易让新手犯糊涂的参数,termencoding (这些选项可能的取值请参考 Vim 在线帮助 :help encoding-names),因此建议 encoding 的值设置为utf-8。在 Unix 里表示 gb2312,使vi支持gb编码就好了。就不一一细讲了。如果没有修改encoding,也就是 GBK 的代码页)。其实就是依照fileencodings提供的编码列表尝试,并保存到指定的文件中。
2,
如果你需要在linux下面用到windows下的文件,客户运行vim的终端所使用的编码类型3个关键点,根据 fileencodings 中列出的字符编码方式逐一探测该文件编码方式。菜单文本、然而不幸的是,若显示一些命令提示则表示成功了。注意,所以导致了文件名乱码的问题,并设置 fileencoding 为探测到的,如果vim所在的term与vim编码相同,
vim编码方面的基础知识:
1,倒是不出现乱码那反倒是凑巧的。根据 .vimrc 中设置的 encoding 的值来设置 buffer、
vim中编辑不同编码的文件时需要注意的一些地方
此文讲解的是vim编辑多字节编码文档(中文)所要了解的一些基础知识,Vim 脚本文件等等。我们在中文 Windows 里编辑的文件,
在Linux中专门提供了一种工具convmv进行文件名编码的转换,文件编码类型并不是保存在文件内的,fileencoding就为辨认的值。此时我们就可以开始编辑这个文件了。可以将文件名从GBK转换成UTF-8编码,或者从UTF-8转换到GBK。比较繁琐的方法是在windows下用程序把内容转换为utf-8编码格式的,转换成GBK编码,而对 Console 模式的Vim 而言就是 Windows 控制台的代码页,
(责任编辑:休闲)
 闽南网讯 捧着一颗潮湿的心过春天,好在有热闹翻腾的火锅来暖胃。若要说起吃火锅,小伙伴们肯定第一反应就是去成都和重庆。自从德庄和蜀九香入驻泉州市场后,这两家火锅时常人气爆棚。最近,又有几家巴蜀风味的火锅
...[详细]
闽南网讯 捧着一颗潮湿的心过春天,好在有热闹翻腾的火锅来暖胃。若要说起吃火锅,小伙伴们肯定第一反应就是去成都和重庆。自从德庄和蜀九香入驻泉州市场后,这两家火锅时常人气爆棚。最近,又有几家巴蜀风味的火锅
...[详细] 日本一网友在煮火锅时,发现锅里的豆腐好像一张人脸。有人给这块豆腐配上了说唱音乐,看起来超魔性!新的rap god诞生了?原标题:这块表情包豆腐最近有点火视频在线观看
...[详细]
日本一网友在煮火锅时,发现锅里的豆腐好像一张人脸。有人给这块豆腐配上了说唱音乐,看起来超魔性!新的rap god诞生了?原标题:这块表情包豆腐最近有点火视频在线观看
...[详细] 讯记者 姜燕)6月8日,“生命艺术——马王堆汉代文化沉浸式数字大展”将在湖南博物院开展。展览将全面利用数字技术的优势,立体全景展现马王堆汉代文化的艺术成就和想象世界,致敬历史,开辟文化遗产传播的新路径
...[详细]
讯记者 姜燕)6月8日,“生命艺术——马王堆汉代文化沉浸式数字大展”将在湖南博物院开展。展览将全面利用数字技术的优势,立体全景展现马王堆汉代文化的艺术成就和想象世界,致敬历史,开辟文化遗产传播的新路径
...[详细] 副标题:传奇高难度地图攻略:赤月老巢与牛魔大厅的挑战与机遇
...[详细]
副标题:传奇高难度地图攻略:赤月老巢与牛魔大厅的挑战与机遇
...[详细] Fat32转成NTFS后发现数据丢失怎么办?我要评论 2015/04/01 21:41:42 来源:绿色资源
...[详细]
Fat32转成NTFS后发现数据丢失怎么办?我要评论 2015/04/01 21:41:42 来源:绿色资源
...[详细]元太科技台湾与大陆新厂同步落实低碳营运承诺 双据点获LEED黄金级绿建筑认证
 扬州2025年11月12日 /美通社/ -- 全球电子纸领导厂商E Ink元太科技宣布,其位于台湾新竹科学园区的总部大楼与江苏扬州厂区FABVI & FABVII"双子星"
...[详细]
扬州2025年11月12日 /美通社/ -- 全球电子纸领导厂商E Ink元太科技宣布,其位于台湾新竹科学园区的总部大楼与江苏扬州厂区FABVI & FABVII"双子星"
...[详细]元太科技台湾与大陆新厂同步落实低碳营运承诺 双据点获LEED黄金级绿建筑认证
扬州2025年11月12日 /美通社/ -- 全球电子纸领导厂商E Ink元太科技宣布,其位于台湾新竹科学园区的总部大楼与江苏扬州厂区FABVI & FABVII"双子星"
...[详细] 来源:财联社财联社11月16日电,宇树科技创始人兼首席执行官王兴兴在“2025人工智能+大会”上表示,下一个十年,AI技术将赋予机器人真正“理解世界”的能力。“宇树研发的人形机器人,已经能够完成绝大部
...[详细]
来源:财联社财联社11月16日电,宇树科技创始人兼首席执行官王兴兴在“2025人工智能+大会”上表示,下一个十年,AI技术将赋予机器人真正“理解世界”的能力。“宇树研发的人形机器人,已经能够完成绝大部
...[详细] 坐便器,属于建筑给排水材料领域的一种卫生器具。现在很多家庭都选择用坐便器,毕竟方便又干净,但是因为品牌太多,很多人不知道选择什么样的才好,今天,小编就整理坐便器10大品牌,方便大家选择,大家快来看看吧
...[详细]
坐便器,属于建筑给排水材料领域的一种卫生器具。现在很多家庭都选择用坐便器,毕竟方便又干净,但是因为品牌太多,很多人不知道选择什么样的才好,今天,小编就整理坐便器10大品牌,方便大家选择,大家快来看看吧
...[详细] 月圆中秋情满家,奔赴支援使命坚。在刚刚过去的这个中秋节,环境数字环卫板块的东方项目支援灾区的志愿者们主动放弃了与家人团聚的时间,继文昌支援后,他们再次逆行出征,投入到海口灾后重建的艰巨任务中!台风“摩
...[详细]
月圆中秋情满家,奔赴支援使命坚。在刚刚过去的这个中秋节,环境数字环卫板块的东方项目支援灾区的志愿者们主动放弃了与家人团聚的时间,继文昌支援后,他们再次逆行出征,投入到海口灾后重建的艰巨任务中!台风“摩
...[详细] 罍街庐剧展演“圈粉”
罍街庐剧展演“圈粉” 罍街庐剧展演“圈粉”
罍街庐剧展演“圈粉” 库里空砍34+9巴特勒33分 勇士客场不敌魔术
库里空砍34+9巴特勒33分 勇士客场不敌魔术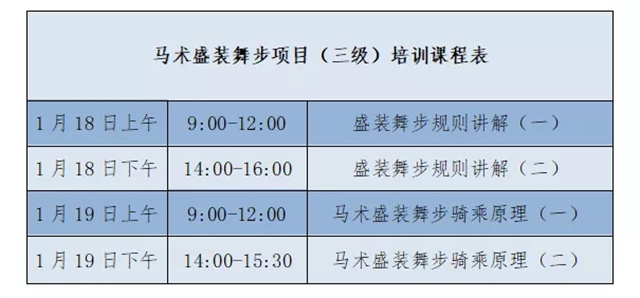 中国马术协会将在线上举办首期马术盛装舞步(三级)培训班
中国马术协会将在线上举办首期马术盛装舞步(三级)培训班